
Where Agentic AI Actually Works
Everyone’s hyped about Agents. AI that doesn’t just answer but does. That acts, reasons, and moves work forward.
But let’s be real: most agentic demos look slick, then collapse the moment you throw real work at them. Why? Because the research is still nascent and companies are still finding their footing. Because agents live or die not just by model size or reasoning ability, but by task fit.
Here’s a sharper lens on where agents shine in the real world, where they stumble, and how to tell the difference.
TL;DR: The wrong question: “What can an agent do?”
The right one is: “How complex is the task? And how easy is it to spot and fix mistakes?” It’s about the task-agent fit.
The Two Axes to Describe your Use-Case
- Task Complexity
- Is your use-case multi-step?
- Is the problem non-deterministic, dynamic, and hard to model using rules?
- Will the agent operate in an unstructured environment?
- Does it require iterative improvement with feedback loops to learn over time?
- Task Detectability + Correctability
- If the agent screws up, will you notice immediately, or only after a lawsuit, outage, or million-dollar mistake?
- Once noticed, how costly are errors to correct?
- Can you measure and correct errors at scale?
- Can human feedback be incorporated into an iterative loop to make the agent more autonomous?
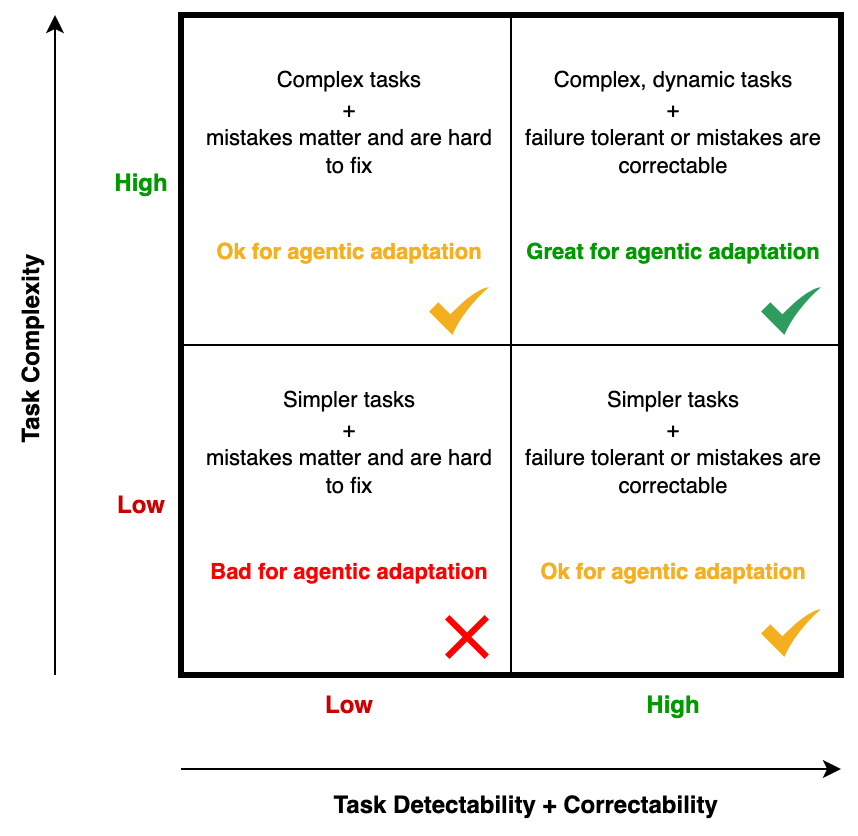
The Four Quadrants of Agentic Applications
1. High Complexity + High Detectability/Correctability
The sweet spot: Multi-step, dynamic tasks where mistakes aren’t costly, or surface fast and are cheap to fix.
Examples:
- Coding copilots
- Customer support with human review
- Sales research
- Marketing content generation
Why it works: Agents can explore, fail, and recover—cheaply. Interactivity and GUIs supercharge this quadrant.
2. High Complexity + Low Detectability/Correctability
The danger zone: multi-step, dynamic tasks where errors are subtle and expensive.
Examples:
- Medical treatment planning
- Financial trading
- Legal contract drafting
Why it struggles: Stakes are high and problems aren’t failure tolerant. By the time you notice a mistake, the damage is done.
Best move: Keep a human in the loop. Agents propose, simulate, explain—but people approve. Add guardrails, dry-run modes, verifiers.
3. Low Complexity + High Detectability/Correctability
Often overkill: simple tasks that don’t need an agent, but chaining small steps with routing logic can still help.
Examples:
- Scheduling meetings
- FAQ chatbots
- Email triage system
- Travel itinerary builder
Why it works (sort of): Errors show up instantly, corrections are cheap. But do you really need an “agent,” or just a good reasoning chatbot + API?
4. Low Complexity + Low Detectability/Correctability
The wasteland: simple tasks where errors are hard to notice and costly to fix.
Examples:
- Compliance document filing
- Subtle configuration updates
- CRM data auto-updater
- Data visualization tool
Why it fails: Too brittle. Too high-stakes. Best solved with deterministic automation or humans.
Levers to Improve Agents
LLMs, LRMs, and in turn Agents have some inherent limitations. They hallucinate output. They have jagged intelligence and can become brittle on obvious tasks. They are limited by context length and fail in long-term planning. They drift from their goal mid-execution. Recovery and self-verification are often fragile.
You can move tasks into better quadrants by engineering the overall system:
- Problem reformulation: Change the problem you’re solving by operating at the right complexity abstraction. Linear workflows don’t benefit from agents.
- Multi-agent collaboration: Planner, executor, verifier. Divide roles, reduce brittleness. Create specialized agents with constrained functions.
- Detection and feedback loops: Design the overall system and UI to have cheap verification checks. Allow for both automatic and human feedback to close the loop.
- Optimal tool use: Calculators, APIs, databases, simulators. Don’t let the model hallucinate what the tool can return precisely.
- RAG, memory, & context: Retrieval for facts. Episodic memory for context. Long-term consistency. Dump logs, intermediate assets to file systems for later consumption. Carefully design the context being passed around.
- Guardrails: Output schemas, validators, tests. Fail early, not downstream. Have guardrails which too are dynamically improved.
- Reasoning models: Beyond raw LLMs. Step-by-step solvers, hybrids with symbolic logic, programmatic pipelines.
Each lever lowers the “cost to detect” or “cost to correct.” That’s how you move risky tasks into safe territory.
The Real Lesson
Not every task wants an agent. Some need a fast autocomplete. Some need a clean API call. Some need a chatbot with reasoning. Some need a human. Be strategic and thoughtful. Don’t follow the hype train into converting all your workflows to use agents. Apply at the right abstraction so the agent has enough complexity and accountability.